

We've been building general-purpose CPUs wrong for decades, apparently. That's the bold claim from Efficient Computer, a new startup stepping into the embedded market with their Electron E1 chip. For too long, our processors have been stuck in a control flow model, constantly shuffling data back and forth between caches, memory, and compute units – a process I think we can all agree that burns significant energy at every step. Efficient’s goal is to approach the problem by static scheduling and control of the data flow - don’t buffer, but run. No caches, no out-of-order design, but it’s also not a VLIW or DSP design. It’s a general purpose processor.

The Electron E1 is designed as a ‘clean sheet processor’ boasting a custom Instruction Set Architecture and ‘smart’ compiler stack. Now, typically, when someone says they have a smart compiler, it’s a red flag - so many instances in this industry of smart auto-vectorization compilers being absolute 💩 for performance. But Efficient Computer claims their chip is built upon a spatial data flow architecture - not as just another AI accelerator in disguise, but a "very general purpose CPU" designed specifically for power-constrained systems like those found in the embedded market.

The numbers they're throwing around are, frankly, somewhat insane. Efficient Computer claims up to 100 times better energy efficiency than ARM's best embedded cores. My ears perked up when they told me they now have working silicon, soon to be available to developers. The fact that this is still a seed startup with its initial funding from Eclipse Ventures showcases it isn't just another academic exercise, even if a number of executives herald from an academic background.
But the embedded market, let's be honest, isn't known for architectural breakthroughs. Most chips in this space are small, low-power microcontrollers built on designs that are decades old. This is partly due to the "tried and true" philosophy and the need for replaceable parts far into the future - being able to have the same chip in use in 20 years is often an absolute requirement. However, the increasing demand for new features, particularly with the rise of AI, and the ever-present power constraints, are pushing these old designs to their limits. We're seeing more features crammed into smaller devices like robotics and wearables, where power consumption is king. Developers want more performance and local AI inference, but power budgets just aren't changing.
My own Huawei Watch GT 2, for example, from 2019, can still last a week on its battery with the screen still on. In most of my posts, I'd say this could be improved with software optimization or shrinking silicon nodes, like a 3nm design. But Efficient Computer, with their E1 chip, is betting that's not enough. They believe the fundamental architecture is what's holding us back.
The Data Flow Paradigm: A Deeper Dive
CPUs, as they stand, spend a disproportionate amount of energy just moving data around – sometimes more than they spend computing with it. Traditional architectures focus on performance, power, or power per operation, often ignoring the data movement overhead. This is precisely the bottleneck in power-constrained embedded systems or systems that run on small custom batteries or cells.
When most people hear "low power chip" or "embedded CPU," they think an in-order ARM Cortex-M or slightly above with something out-of-order in the architecture, paired with enough on-chip memory or some DRAM off-chip. The model is simple: a small processor fetching, decoding, ordering, scheduling, executing, then retiring pipelined instructions step-by-step, moving data to and from memory as need.
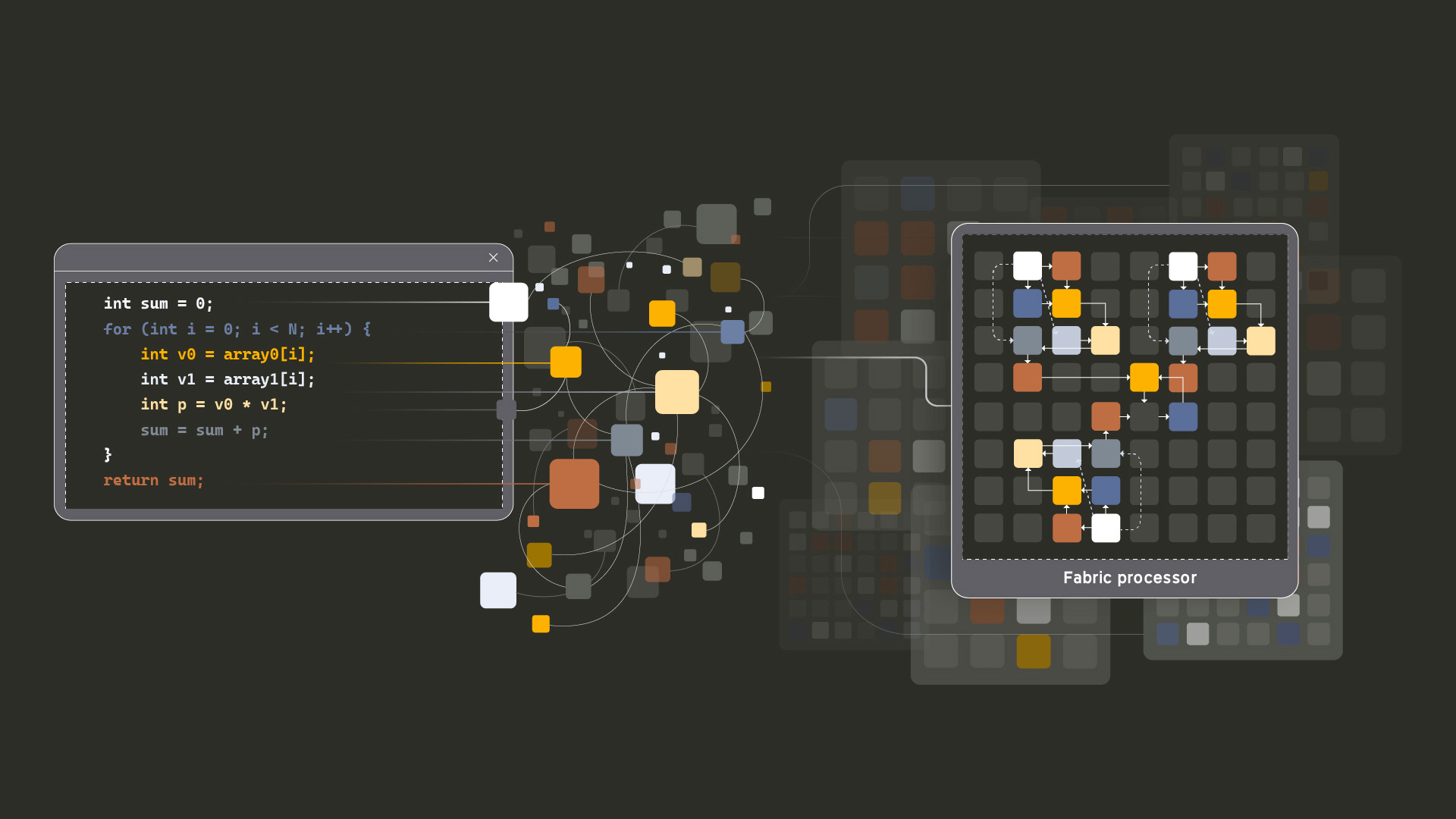
Efficient’s architecture, called simply "Fabric," is based on a spatial data flow model. Instead of instructions flowing through a centralized pipeline, the E1 pins instructions to specific compute nodes called tiles and then lets the data flow between them. A node, such as a multiply, processes its operands when all the operand registers for that tile are filled. The result then travels to the next tile where it is needed. There's no program counter, no global scheduler. This native data-flow execution model supposedly cuts a huge amount of the energy overhead typical CPUs waste just moving data.
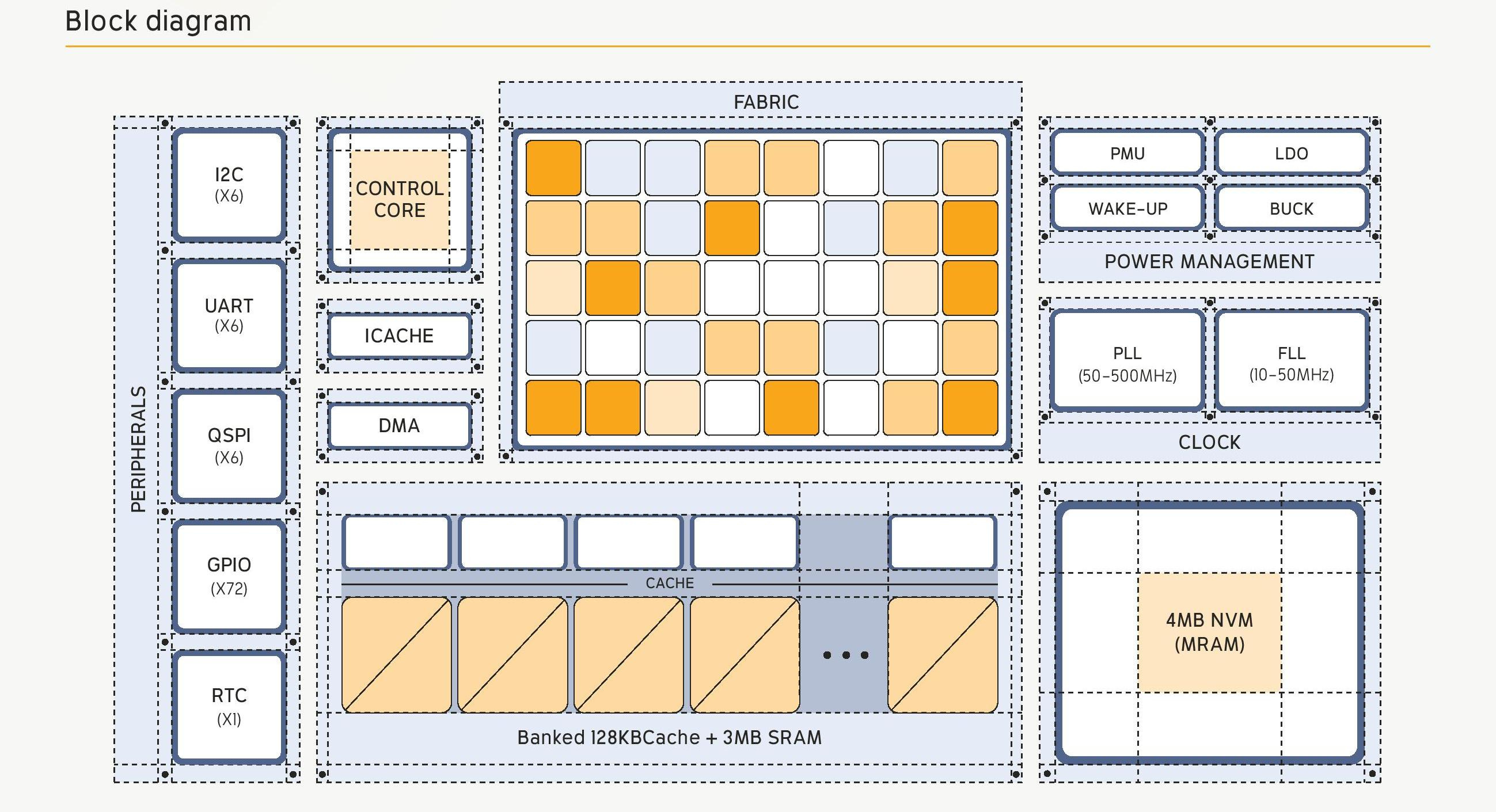
Under the Hood: Tiles, Graphs, and Compilers
The Electron E1 is essentially a grid of small compute tiles, each capable of basic operations like math, logic, and memory accesses. The compiler statically schedules each title to be what it needs to and route the data. The Efficient compiler converts the C++ or Rust code in a data flow graph - and that’s a key point here. By being able to run regular C++ or Rust, that’s why Efficient is saying it’s a general purpose CPU.

Of course, this introduces its own challenges. What happens if your program graph is too big for the chip? Efficient tackles this with pipeline reconfiguration - the compiler breaks the graph into chunks, and the chip dynamically loads new configurations as execution progresses. Each tile even has a small cache of recent configurations, so loops and repeating patterns don't force a full reload every time.
The interconnect between tiles is also statically routed and bufferless, decided at compile time. As there's no flow control or retry logic, if two data paths would normally collide, the compiler has to resolve it at compile time. This keeps the fabric incredibly power-efficient but pushes a lot of responsibility onto the tool chain. Relying on a ‘perfect’ compiler has been an issue in traditional computing, so it'll be interesting to see how this plays out.
A meaningful milestone for the Electron E1's first release candidate chip is its support for 32-bit floating point. Many low-power architectures are integer-only and operate in a fixed-point math format. The CEO, Professor Brandon Lucia, emphasized that 32-bit was necessary for the architecture's ability to scale.
Crucially, this isn't software-emulated data flow; the hardware is designed to be the data flow engine. Whether that's flexible enough for real-world embedded software or if it creates too many edge cases remains to be seen. Architecturally, it's about as far from conventional CPU design as you can get while still claiming ‘general purpose’. That's supposedly where the power benefits lie.
The Software Story: Is It Truly Developer Friendly?
The Electron E1 uses standard tools; the compiler front-end is based on Clang and supports both C++ and Rust as previously mentioned . They also state support for machine learning frameworks like PyTorch, TensorFlow, and JAX , though the level of manual intervention required to enable those isn't clear yet.
The tool chain, effcc, was previously just a sandbox compiler playground. With the E1's release, it's now fully downloadable, meaning developers can integrate it directly into their workflows and target real silicon. EFCC takes regular code and lowers it into Fabric's spatial data flow model, handling graph decomposition, operation mapping to tiles, configuration generation, and pipeline management. In traditional compilers, these decisions happen dynamically at runtime; here they're resolved statically at compile time. This compile-time resolution is where the efficiency comes from, but it also means the compiler has to be pretty intelligent.
Leaning into my earlier point about "magic compilers," a lot of the secret sauce is undoubtedly in that tool chain. Efficient promises developers won't need to learn a new mental model to get started – just write C++, and the compiler handles the mapping. My biggest question is what happens when something doesn't map cleanly or the compiler hits a corner case. Will the developer get visibility into what went wrong? Or maybe I’m thinking to much like a high-performance silicon programmer, who has performance tools at their disposal. Adoption of a new paradigm like the E1 will likely hinge on how robust that tooling truly is once developers start stress-testing it in the wild.
Performance Claims and the Road Ahead
Let's circle back to performance, specifically energy efficiency. Efficient claims the Electron E1 delivers 10 to 100 times better energy efficiency than market-leading embedded ARM CPUs, specifically naming Cortex M33, M85, and A5 class cores. The core metric here for Efficient is "operations per joule," which is a fair one if you're designing for battery life. That's the right question: how much useful work do you get per unit of energy?
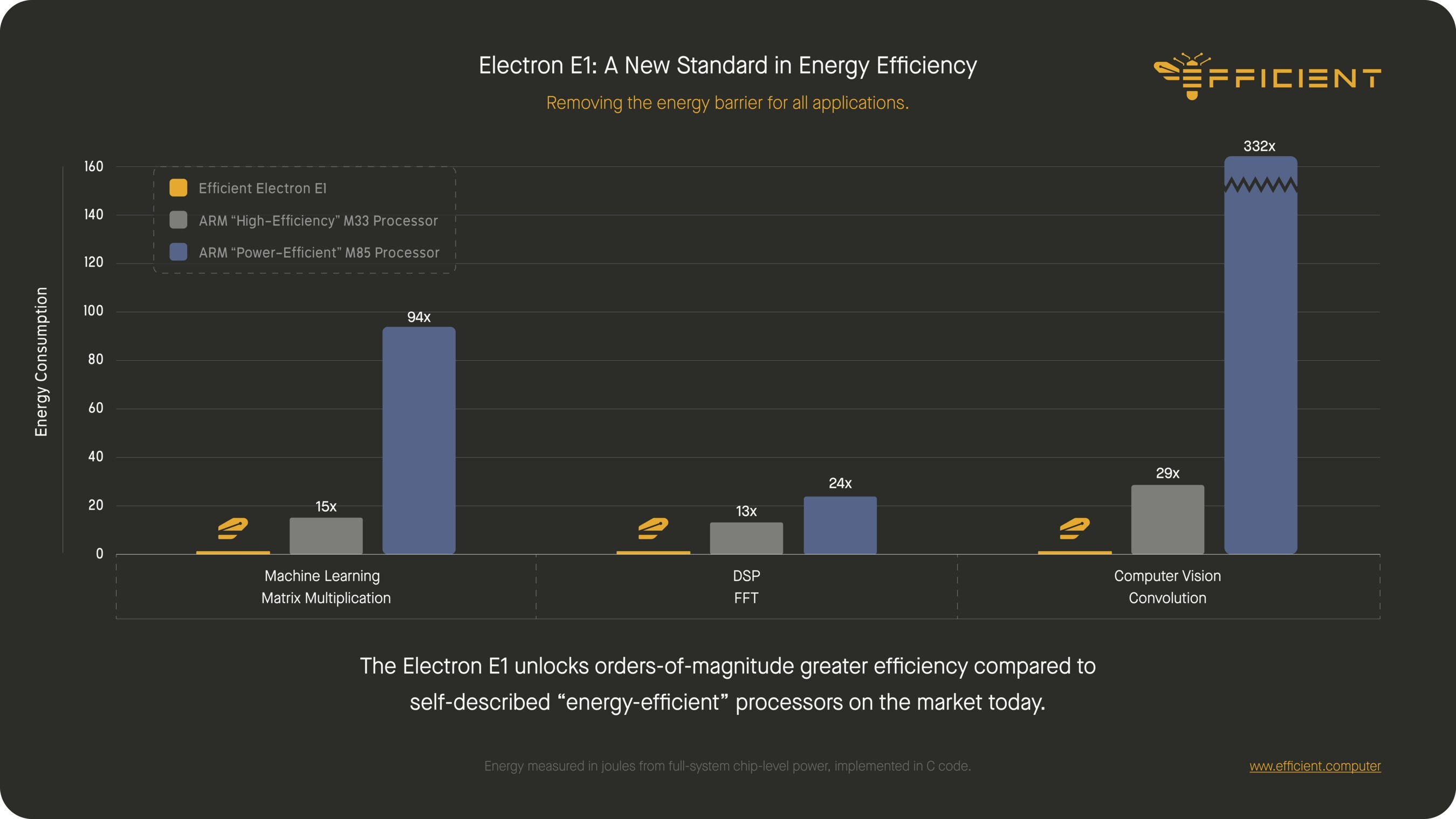
However, the CEO also highlighted "TOPS per watt" as their key metric. And frankly, TOPS per watt causes me a little concern. TOPS per watt is typically an AI accelerator metric, not one for a general-purpose CPU. It's also precision-dependent, and while the E1 supports FP32, comparing TOPS for a general-purpose CPU starts to drift into the kind of performance marketing we usually see from machine learning silicon, not embedded silicon. There’s also the fact that traditional CPUs might have large vector engines, obscuring the true serial performance. I’d add here that most embedded benchmarks are highly traditional, like DMIPS or Coremark, and many embedded processors don't even list TOPS. I'd really love to see SPEC2006 run here, as I know for a fact that a lot of Arm’s embedded customers still rely on that data in their evaluation toolkit
Still, the 10-100x energy efficiency range isn't necessarily implausible, given how conventional CPUs burn power on data movement. To their credit, Efficient has shown silicon at events, has shown internal benchmarks to customers, and is getting ready to send developer kits out. But until we see full workloads and independent validation, it's hard to know how much of that advantage holds up across various use cases. Embedded developers also care about memory footprint, interrupt latency, reconfiguration time, I/O contention, and software compatibility. Those factors will likely matter just as much as the efficiency claim.
Looking ahead, the Electron E1 is just the first step in Efficient's roadmap. They're planning a full product family, including a second-generation E2 and something much, much bigger called the Photon P1. The plan is to scale the architecture up in performance, broaden workload support, and offer both standalone SOCs and licensable IP – a familiar strategy for startups. For Efficient, the current focus is on systems where energy matters more than peak throughput: aerospace, defense, industrial sensing, wearables, maybe even space systems. Anywhere compute needs to live for a long time on limited power with minimal maintenance.

What makes this moment interesting is that they've now crossed the line from research into product. I saw the early E0 version at CES 2025. With E1 now available, at the very least, it'll be able to answer harder questions, such as whether the world is ready to adopt this new execution model, especially in the embedded market where reliability and predictability matter more than novelty.
Compiler maturity, debug tooling, supply chain commitments, and production ramp – all of that still lies ahead for Efficient. The embedded sector's demand for parts availability for over a decade makes it a brutal market for a startup. We've all heard stories of modern aircraft relying on '80s and '90s processors that are no longer in production, forcing reliance on stock piles as that hardware went EOL.
But if it works, if it scales, Efficient may have done something we haven't seen in a very long time: built a general-purpose CPU that didn't just evolve from the last one. It's an interesting take for sure, and I hope we get a deeper look into how the architecture works soon.
I just have one question left. Doom? Can we compile Doom?
Have they published their ISA? I wonder if the approach is scalable to very different contexts, like some future PIM system that consists of just a big array of smart-dimms on some sort of switched fabric.
When I hear about compile-time resolution (vs. runtime resolution) it makes me think about the insanity of what was Intel Itanium...