

Scaling up Quantum to 100 Million
Scaling up Quantum to 100 Million
Updates from IBM Quantum Summit

Companies mentioned: IBM 0.00%↑
Quantum computing, as a technology, plans to disrupt three main areas of computing:
The physical world - we're talking chemistry, physics, material science
Optimization - finding global minima in a multidimensional problem
Machine Learning - because of course it is
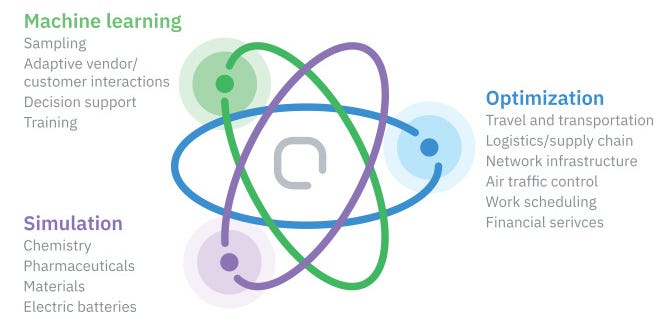
In order to make a quantum computer useful in any three of these areas, you need (a) enough qubits to matter, and (b) to keep them stable for a good length of time. The base compute function is the quantum circuit, and in order to have detailed computation in a quantum system, you need to be able to run these circuits with qubits that last a long time, and have enough qubits to showcase the variables within the problem.

To date, most of the focus has been on the number of qubits in a system. With each new qubit in the system, the number of things you can model is doubled. This means that the jump from 2 qubits to 5 qubits to 13 qubits to 20 qubits is massively scaling up the computational surface of problems that could be tackled. Now of course, there's no real reason to use quantum computing for something that could be done in conventional computing, however conventional computing resources run out modelling around 42-43 qubits, and that's with large amounts of cloud resources. And so at this time, we're starting to see companies showcase systems with 100-200 qubits, and talk about scaling up to 1000.

However, one of the big issues with modern quantum computing is stability and error. If you've heard of presentations about quantum computing, many showcase the requirement for hundreds of thousands, if not millions of qubits, in order to deal with error mitigation. Because of the stability of qubits and the nature of the computation, computational results have to have substantial error mitigation, with some researchers in this field suggesting that for every 100-1000+ physical qubits, the reality is that we only get a single logical qubit. Error mitigation is one thing, but also error correction is another, and it's a technology still in development. But it means that even for large qubit systems, without a way to tackle the errors, having hundreds or thousands of qubits is still scratching the surface.
It's at this point in the conversation when the question comes about as to 'if anything useful has been done on quantum computers yet'. In the last six months, let's point to the following.
Quantum Utility before Fault Tolerance, 127 qubits, Nature, 618, 500 (2023)
Simulating spin-chains, 102 qubits, arXiv:2207.09994
Uncovering local integrability in many-body dynamics, 124 qubits, arXiv:2307.07552
Reservoir computing with repeated measurements, 120 qubits, arXiv:2310.06706
Realizing the Nishimori transition, 125 qubits, arXiv:2309.02863
The Schwinger Model Vacuum, 100 qubits, arXiv:2308.04481
Long Range Entanglement simulation, 101 qubits, arXiv:2308.13065


If we go through some of the largest quantum engagements, we see that a number of companies are actively doing research into the viability of quantum computers to assist their problem solving skills.

In short: it's real and it's here. That Nature paper at the top of the list is quite significant announcement, showcasing a real-world problem (called a transverse 2D Ising model) that a quantum machine was able to complete faster and more accurately than the best classical computing could offer. At the time, I did a video going deeper into the topic:
One of the key elements to that research was the error correction methodology, using a simulated noise injection technique to calculate the amount of base error in the computation. By injecting noise at different levels, it created a scalable result which could be extrapolated to a no-noise result, giving the final answers. This technique was dubbed ‘zero noise extrapolation’, or ZNE. This is one tool in the toolbox to assist for quantum computers, and helping decrease the number of qubits needed for real world scenarios.
The other angle to touch on that's important for quantum computing, but sometimes goes under the radar, is the number of gates that can be run in a system. We've spoken about how qubits are only stable for a short amount of time - this amount of time is known as the coherence time , or how long you have before the qubit is no longer useable. In that time the goal is to run as many circuits and the gates through the qubits as possible in that time period. For a modern quantum computer of 100 gates, such as those in the papers above, ~3000 CNOT gates were run within the coherence time of the system. The more CNOT gates you can run, the longer a calculation is supported.
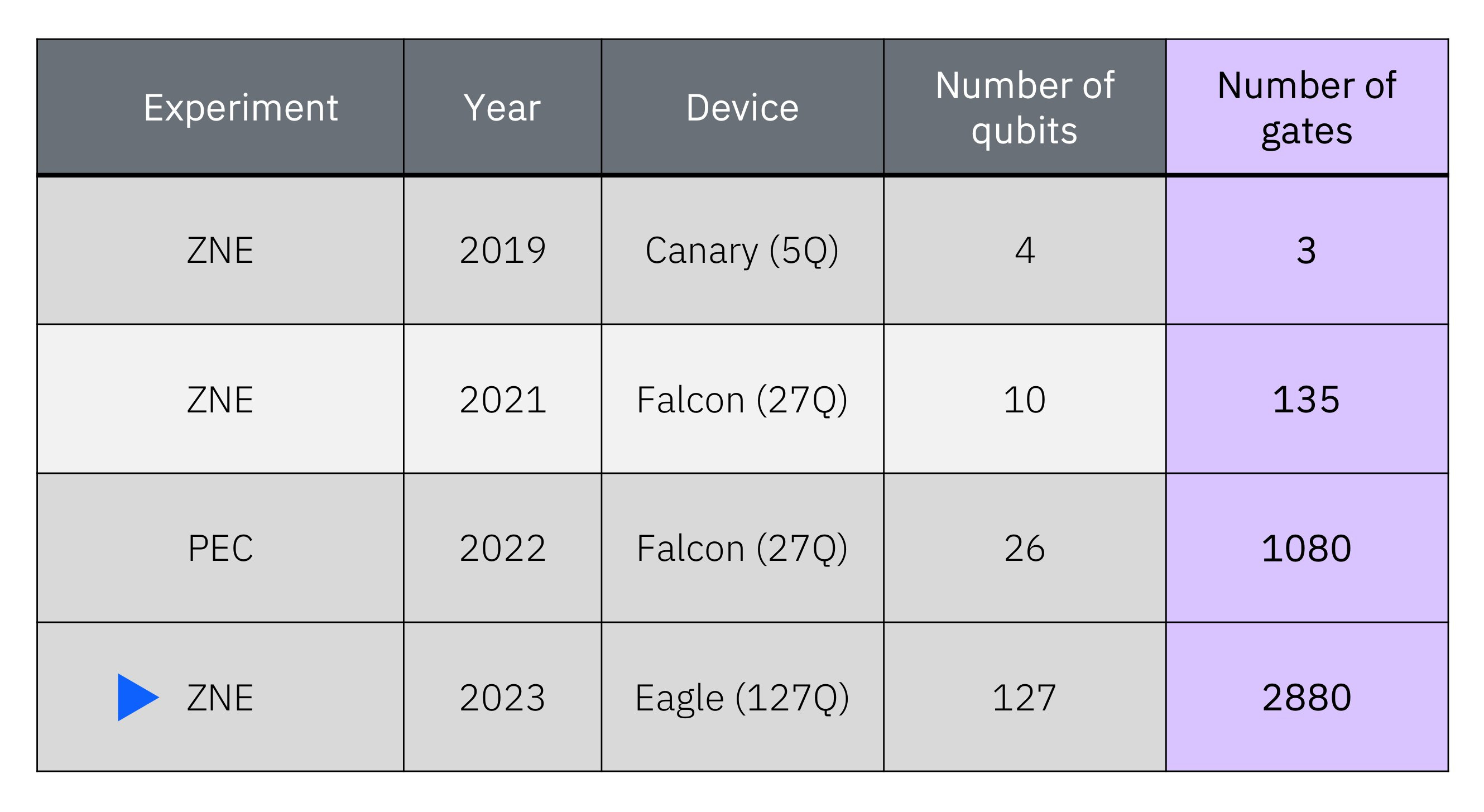
Both coherence time and gate length ties in with error correction and error mitigation. The technique requires accurately manufactured qubits, and then optimized tools on top to get the best out of it. As we'll see later in this piece, there are techniques not too dissimilar to optics that are being researched to help increase this coherence time.
The best way to think about it is that:
more qubits = more complexity, whereas
better coherency times = more gates = longer programs
A modern high-end system of 100 qubits can have coherence times in the 10s or 100s of microseconds. The time to run a gate isn't constant - it varies on the local environment of the qubit - but can be anywhere from 10 to 1000 nanoseconds. There are also optimization layers in software to take a circuit and make the gates as fast as possible.
The future of quantum computing isn't simply about scaling qubits anymore. Scaling qubits is hard. Scaling anything is hard. As part of IBM's disclosures at their Quantum Summit, the company showcased the roadmap is going after both qubits and gates in a very big way.
IBM's Roadmap to 2033: Innovation
The Quantum roadmap from IBM is now going to be split into two tracks. One is around innovation - the act of finding the best way to accelerate the features in quantum hardware by building qubits and building new technologies that help scale qubits by connected them together, both across chip and from chip to chip. Here's what that looks like.
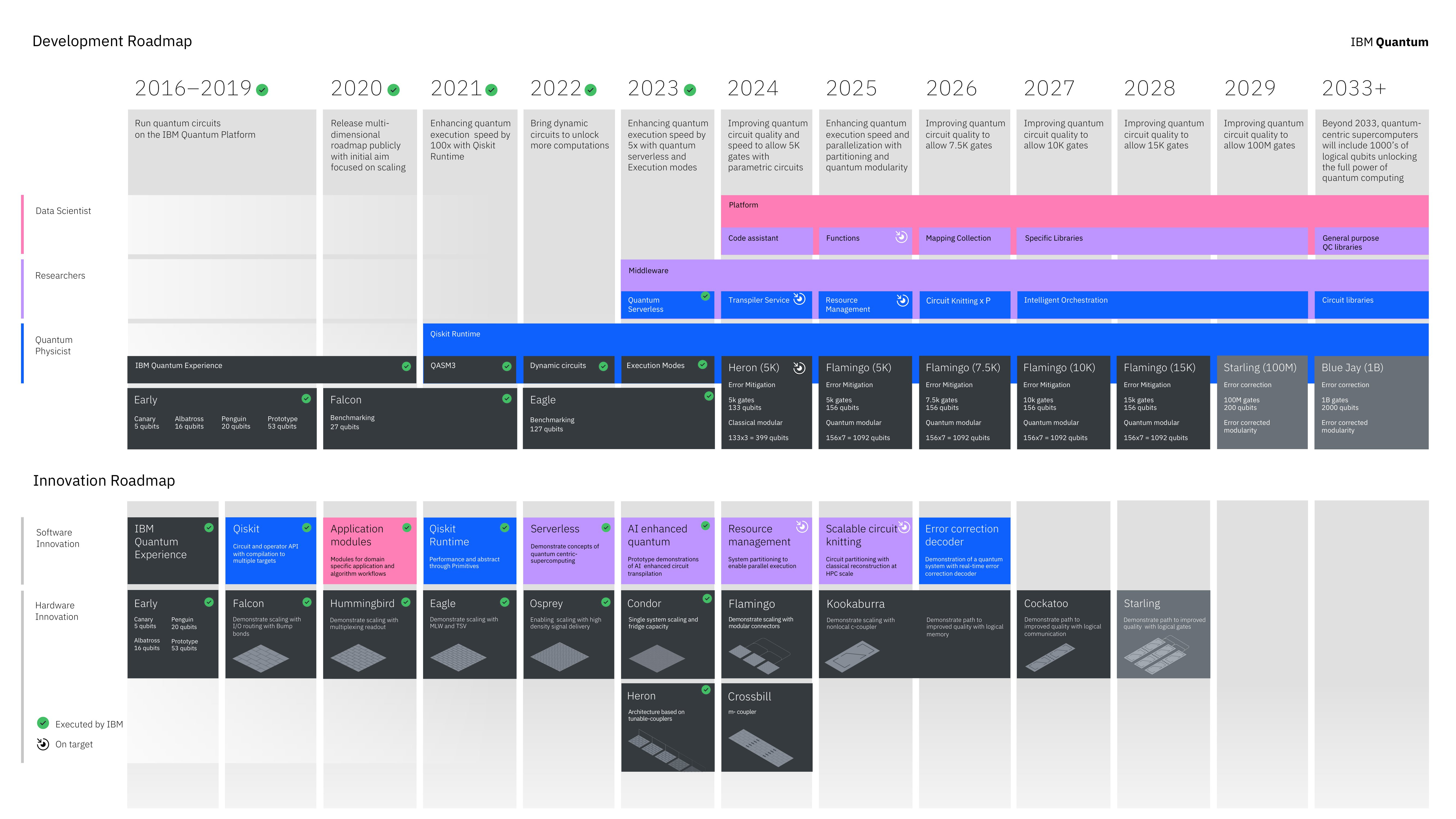
The roadmap is quite dense, but here’s what it says under the Innovation section.
2016-2019: Early chips
Canary, 5 qubits
Albatross, 16 qubits
Penguin, 20 qubits
Prototype, 53 qubits
Falcon, 27 qubits - scaling with IO routing with bump bonding
2020:
Hummingbird, 65 qubits - scaling with multiplexing readout
2021:
Eagle, 127 qubits - demonstrate scaling with MLW and TSV
2022:
Osprey, 433 qubits - scaling with high-density signal delivery
2023:
Condor, 1121 qubits - single system scaling
Heron, 133 qubits x p - multi-chip architecture with couplers
2024:
Flamingo, 1386+ qubits - multi-Heron chip scaling with modular connections
Crossbill, 408 qubits - tightly coupled Heron chips with m-couplers
2025:
Kookaburra, 4158 qubits - scaling with non-local c-couplers
2026:
Kookaburra with improved quality with logical memory
2027:
Cockatoo - tightly coupled multi-Kookaburra with improved quality with logical communications
2028:
Starling - multi-Cockatoo with modular connections
This year, IBM has introduced Condor and Heron. Condor is the biggest single chip quantum processor every produced, with the marketing materials saying that it pushes the limits of scale and yield. Through manufacturing innovations, IBM says they can enable a 50% increase in qubit density with Condor.

Users who only focus on single chip qubit scaling will say this isn't enough to hit a million qubits, but there are stepping stones, just like with regular chip manufacturing today. IBM manufactures its qubit chips in house, and the key metric that IBM is proud of here is the coherence time of Condor qubits - the first revision is within a whisker of the coherence time of the best Osprey chip they've produced.

As we can see, the slides point to innovation in the superconducting metals and the planarized dielectric. I'll have to do research into qubit fabrication to see what that actually affects.
Also in 2023 sees the introduction of Heron. Heron is only 133 qubits per chip, so smaller than Osprey, but introduces a new concept of tunable couplers. This means that the qubits on Heron can be tuned post-manufacturing to provide either better coherence times or shorter gate times. Heron is designed to minimize gate error by eliminating crosstalk, and as a function, increase throughput.

The numbers IBM put out there compare the first generation Heron R1, to the third-generation Eagle R3, which are similar in qubit size. The third generation of Eagle has a higher T1 coherence time of 269 microseconds, but it takes 537 nanoseconds to run a gate, enabling only 500 gates within that time. Heron R1 on the other hand, despite the shorter T1 coherence time of 174 microseconds, takes only 96 nanoseconds to run a gate, showcasing a 3-4x improvement in throughput. This would be like improving your CPU frequency by a factor 3-4.
The goal here is that orthogonal to the number of qubits growing, coherence time and gate time matters. As the gate time comes down, the number of gates that can be run will increase dramatically.
I like the concept of tunable couples that help optimized the qubit after manufacturing because it reminds me of a similar technique used in optical systems. More often than not, optical systems that need accuracy to the picometer or less, you're relying on the manufacturing to get it right, first time. Manufacturing is a fickle beast, even in small batch systems, so there has to be a way to configure a coupler or a resonator to the right wavelength after manufacturing has taken place. In an optical system like a microring, we might think of a thermal jacket around the ring, that can form/deform the ring until it hits the right wavelength, and then gets fused off at the right value. I have a feeling that the tuned couplers in this case are doing similar to the entanglement between qubits, enabling this minimized crosstalk.
Also a highlight of 2023 was the concept of couplers to help with error mitigation and modularity. Right now IBM's chips are built with a heavy-hex architecture. It's that design that kind of looks like bricks in the wall with qubits at every point. At each point, qubits are connected to their nearest neighbors, which is usually 2 or 3 qubits, and it's those qubits that they can entangle with to create gates. What IBM is looking at for the future is the ability to create those connections to other qubits across the chip, or across to other chips. This is called long-range or non-local connections, or coupling.

C-Couplers are the easiest ones to conceptualise, and occur within the same chip.
M-Couplers are for chips in close proximity, joining multiple chips together
L-Couplers enable larger scale systems entirely
It's almost akin to thinking about cores in a chip, vs chips in a system, vs chips in a rack. Using types of couplers enables scale out of the chips in terms of memory, communication, and coherency. With Heron, we start looking at C-couplers, with M-couplers coming in 2024 with Crossbill. C-couplers are then scaled out in 2025 with Kookaburra, with L-couplers coming out afterwards
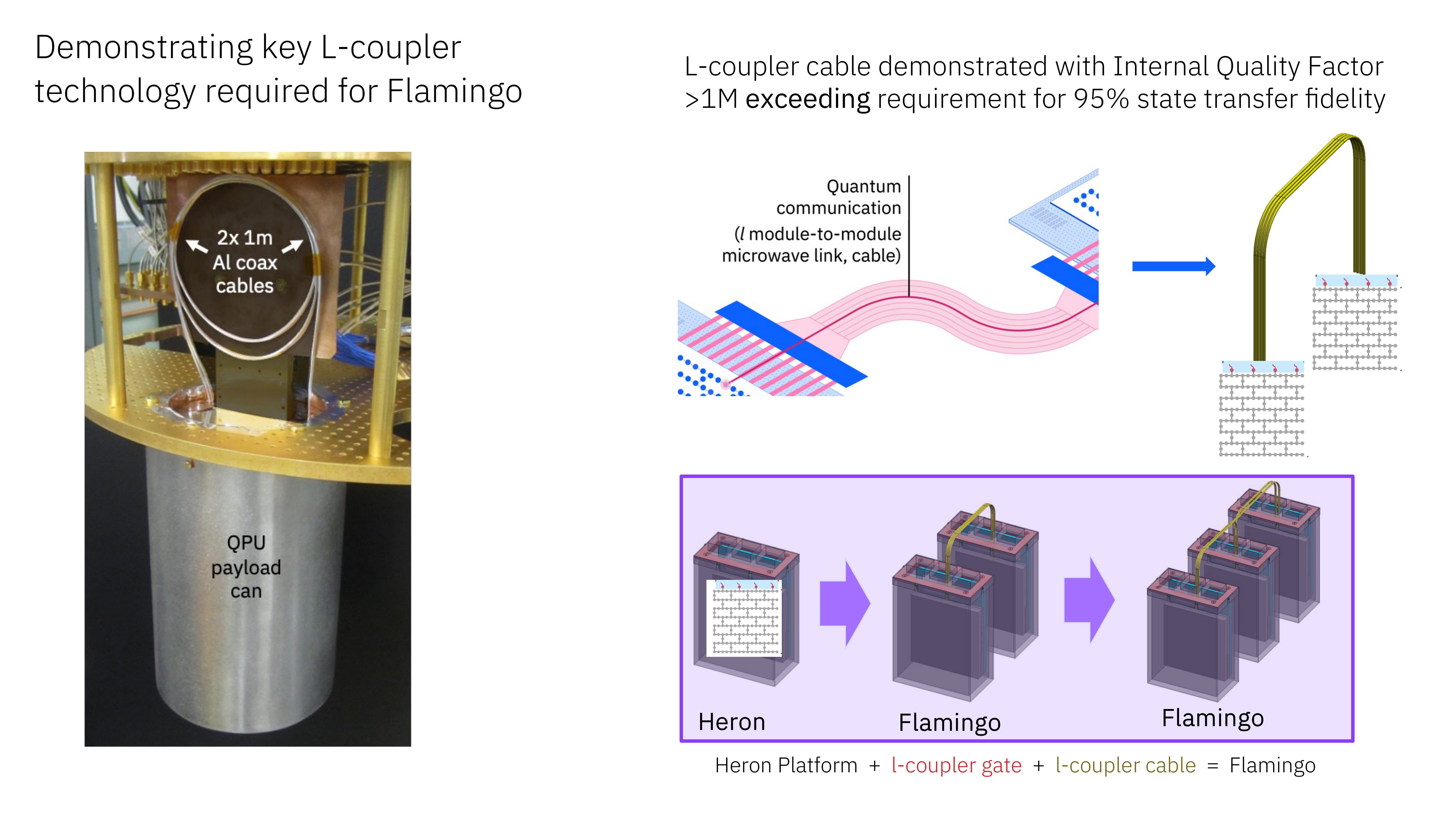

The point that IBM is trying to make with this innovation roadmap is how does the number of qubits scale. The type of qubits that IBM focuses on, the superconducting qubits, are physically limited to how many can fit on one chip - as a result, connections between chips become the main focal point. The first question is how, the second question is where, and the third question is 'does it work'?
IBM's Roadmap to 2033: Development
The second half of IBM's roadmap is development. This is all about productisation, software, security, and platform. It gets quite detailed, and I love to focus on hardware, so let's start there. This is also where the big numbers come into play.
2020-2021: Falcon, 27 qubits
2022-2023: Eagle, 127 qubits, 3000 gates
2024: Heron, 3x133 qubits, 5000 gates
2025: Flamingo, 7x156 qubits, 5000 gates
2026: Flamingo, 7x156 qubits, 7500 gates
2027: Flamingo, 7x156 qubits, 10000 gates
2028: Flamingo, 7x156 qubits, 15000 gates
2029: Starling, 200 logical qubits, A HUNDRED MILLION GATES
2033: Blue Jay, 2000 logical qubits, A BILLION GATES
Let's start with the monster number: A HUNDRED MILLION GATES in 2029.

It's quite a jump from 15000 gates in 2028. Earlier, we reported that Heron R1 was able to perform 1800 gates within the T1 time - with an average T1 time of 174 microseconds and an average gate time in 96 nanoseconds. Divide 174000 by 96 and we get about 1800. Let's think for a second on how to get to a hundred million.
In order to reach that number, let's consider a gate time drop down to 10 nanoseconds - something simple, and an order of magnitude in six years. For there to be 100,000,000 gates at that time, the coherence of a qubit must be a full second. Today, the best performing individual qubits is around 500 microseconds - we're talking at the top end of the distribution. To go from 500 microseconds to a full second is a 2000x improvement. Insane.
This means that IBM is predicting the equivalent of a 20000x improvement in their quantum systems between today and 2029.
One question is - what will this enable? Being able to run 20000x more gates allows for longer computation. Part of the dilemma of quantum computing is that if you have a million qubits, but you can only run a handful of gates, then the complexity isn't exploited if there's no depth to the calculation. Having access to all these gates means a substantial increase in the depth of the work. More gates means more compute, rather than more complexity - sometimes you just need the time to compute more, rather than a new step function in complexity.

In order to build a Starling system, IBM is showcasing that this will require around 10 dilution systems using the latest generation couplers. One of the key features here to nail down is the system-to-system connectivity, as described earlier. Blue Jay, is another step beyond.
Software
Now at this point in the article, you'll notice I haven't mentioned much about software. Software is a key integral part of these systems, however it's not something I usually focus on. What I did want to showcase was a few of the features in the Quantum toolkit QISKIT v1.0.
IBM splits up problems into four software component stages:
Map classical inputs to quantum problem
Optimize problem for quantum execution
Execute problem
Post-process and return in classical format
For each of these stages, IBM has improvements to share. On the first step, with the launch of v1.0, the circuit and operator toolkits are showing a 55% decrease in memory usage required to map problems to what the quantum computer will run.

On the optimization side, these quantum circuits are then sent through a transpiler, which converts the circuits into a quantum instruction set based on the hardware. Here we also get features that optimize circuit performance, e.g. predicting shorter gates, or helping reduce natural errors in the process. Compared to older toolkits, this is a 16x speedup on transpilation, and a reduction of total gates by about a third.

What's more than that, IBM is already using AI to help with the transpiler. At the event, a proof of concept scenario was showcased, with the machine learning model doing better than the standard algorithms to the tune of 20%-50% circuit depth. This is a work in progress but showing good results this early on. I particularly like the diagrams on the right, showing how ML has changed the compute.
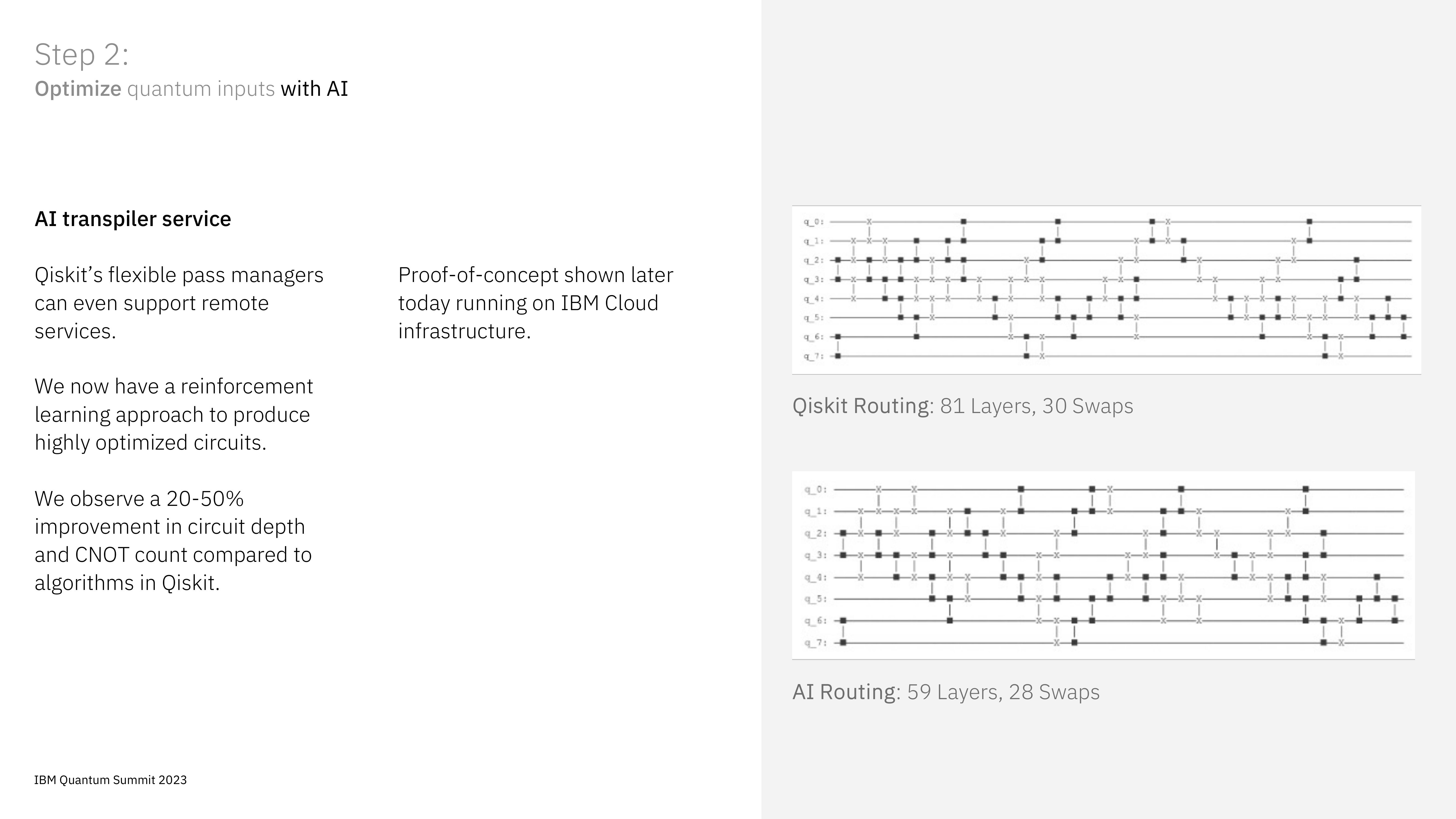
In the third stage of execution, the focus here is batched or session execution. As with any other system, quantum computers also have multiple users running circuits, and the question is whether some of these workloads can be batched to run simultaneously but not affect each outer. This is essentially parallelizing non-collaborative workflows, except it has to be run at compile/execution time. IBM is claiming a 5x faster throughput with batch parallelism.

For post-processing, we get into some of the error correction techniques mentioned earlier.
Quantum System Two
The final announcement at IBM's Quantum Summit was the launch of its Quantum System Two.

IBM has had Quantum System One for a while - a turnkey solution for 127 qubits. IBM has several of these available in the cloud, ten at research institutions currently installed, and more for research on the order books. (The number not for research institutions hasn't been disclosed). These systems, I believe, can be upgraded with bigger single chip qubit solutions as they are qualified.

System Two, however, takes a more modular approach to deployment. We discussed up above Heron - three 133 qubit chips joined by couplers. Each chip requires its own dilution environment, and System Two does exactly that -it combines three quantum computers into one. As a result, they can act like one combined system, or three separate ones. The modular layout allows the system to evolve with IBM's roadmap for the next several years, in terms of control, support, and expansion.

IBM currently has a System Two at the Thomas J. Watson Research Facility in Yorktown, NY. If you get invited to visit the campus, it's in the Think Lab to the left as you walk in - IBM have put it front and center in the area they want to show to visitors, and it's there being used to run tests and circuits.
The answer to ‘Does anyone use IBM?’
On top of all this, the VP of IBM Quantum Jay Gambetta posted this on LinkedIn this week. The total number of circuits run on IBM Quantum machines has surpassed 3 trillion.

Now to do the math on that and work out how many quantum system hours that represents...